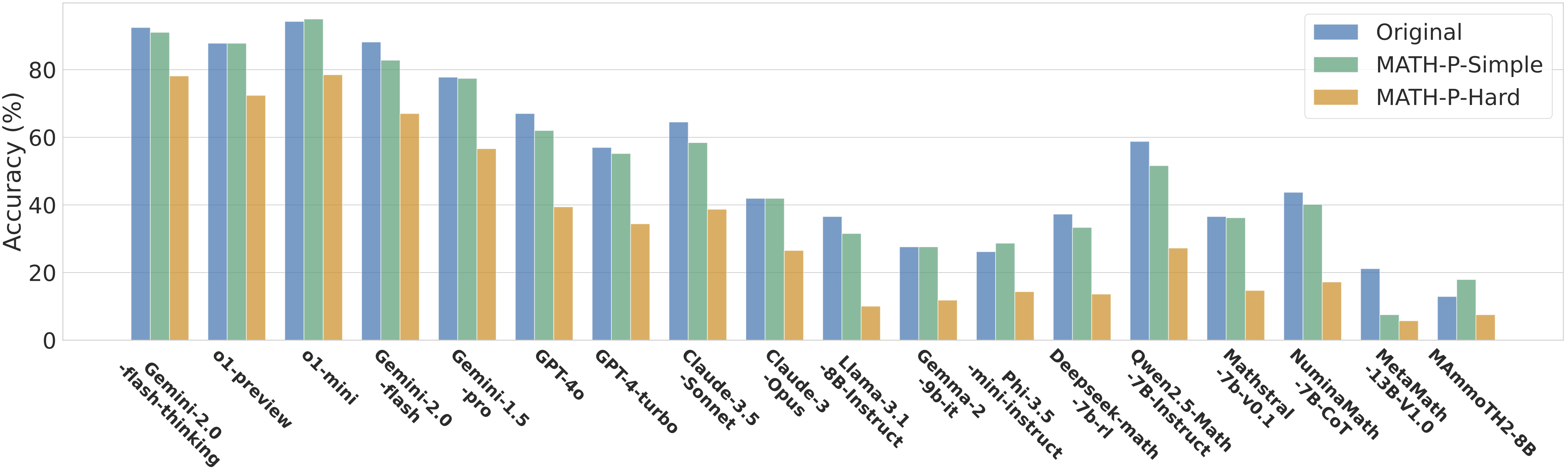
 We observe significant performance drops on
We observe significant performance drops on Note: For DeepSeek-R1 series, we use the suggested configuration (temperature=0.6, top_p=0.95) and set the max length to 65536 (64k) tokens. For QwQ-32B, we adopt a max length of 32768 (32k) with temperature=0.6, top_k=40, top_p=0.95. For Claude-3.7-Sonnet extended thinking mode, we use thinking budget tokens = 56000 and max tokens=64000.
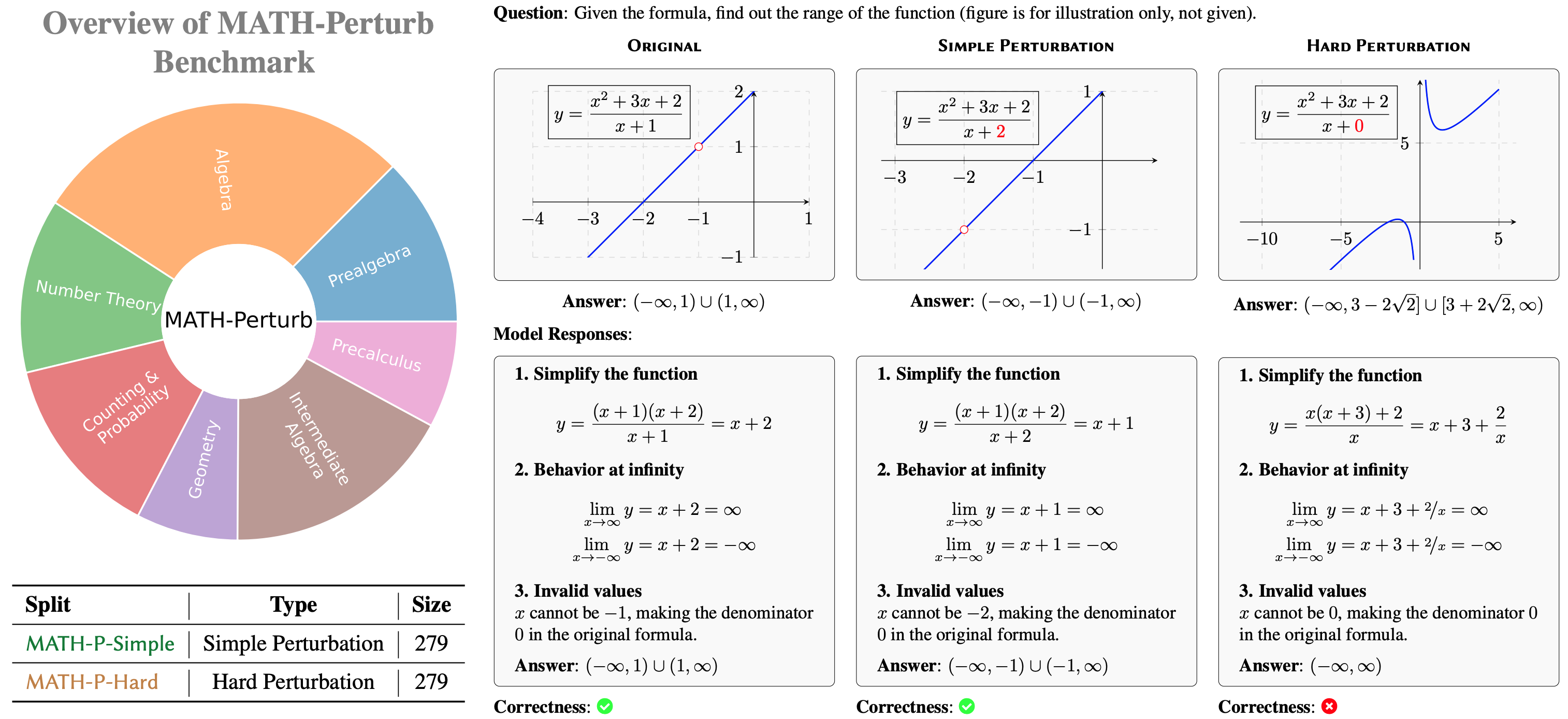
Left: The overview of MATH-Perturb Benchmark. Right: An example of the original problem, its simple perturbation, its hard perturbation, and the corresponding model responses that overfit the short-cut solution. The simple perturbation to the problem is non-essential, so the modified problem can be solved using the same method as the original problem. The hard perturbation changes the problem fundamentally and it requires more difficult problem-solving skills. The shortcut solution can solve the original problem and its simple perturbation but fails on the hard perturbation.